Chapter Introduction: Model Tracking and Retraining
Our model is now in production. Hooray! One distinction of machine learning systems is they generally decay over time. This concept is sometimes difficult to grasp for the non-initiated into data science. A machine learning system is not like a website; we can't just prop it up and let it be. We need to monitor it closely, and we also need to retrain our model.
Data science projects are never done, barring getting canceled. Like a car, our model needs maintenance. Retraining your model on new data might be like your regular oil change. Occasionally you might need a bigger repair, like replacing a gasket. In machine learning, this might be akin to completely changing models (e.g. from Random Forest to XGBoost). Fortunately, some of this can be automated via AWS Batch and our CI/CD pipeline. We can schedule our model to retrain and be released into production. We can leverage our testing mechanisms to ensure a "bad" model does not go into production.
You might ask: How often should we retrain our model? My answer: it depends. The decision is contingent on how stationary the environment is. For a stock trading models, frequent retrains are likely warranted (e.g. daily or multiple times per day). For our customer churn model, the environment is very likely not as dynamic. That said, we probably don't want to go many, many months without retraining the model. Over the course of months, multiple items with the business or broader environment might change. Likewise, as months go by, we might see new types of customers the model did not experience during training, or churn rates for certain types of customers might systemically change due to broader marketing efforts. Using only a rule of thumb, my professional opinion would be to retrain the churn model every few weeks or even every few months. We likely would not experience enough day-to-day change to warrant more frequent retrains.
We could trigger a model retrain based on underling conditions. For one, we could track predicted vs. actual outcomes and have the model retrain once performance drops below a certain threshold. In environments with quick feedback mechanisms, this can work well. What's more, we could track the business impact of our model over time and trigger a retrain when this impact starts to decay. This can be a bit reactionary as it might take time for business impact to shift or be measures.
We have other related options. We can assume we would be getting new churns on a somewhat regular basis. These would represent updates to our training data. As these updates come in, we could see if they notably shift the relationship between the target and the features. For example, clients with a certain creative_id start churning at a much higher rate. This is known as concept drift. Likewise, we might also experience dataset shift, which is when the distribution of a feature changes over time. For instance, the profile_score's mean and standard deviation might shift much higher. We can monitor both concept and dataset shift and take action accordingly.
Given all these options, what option should we choose? Again, it depends on the environment and overall modeling problem. That said, I posit the following relationship exists generally.
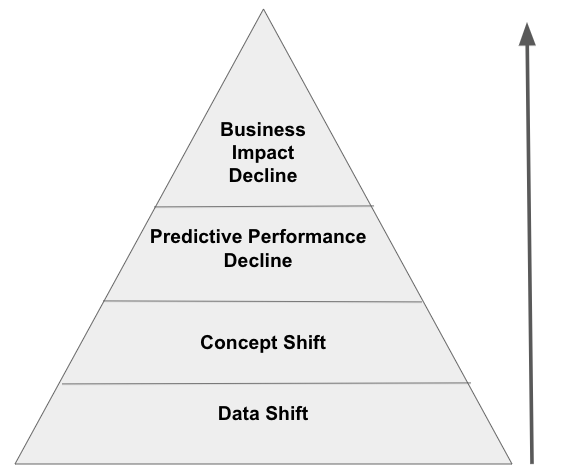
Data shift leads to concept shift. Concept shift will produce declines in predictive performance, which will hamper business impact. Our retraining methodology should generally follow this path as well. If we retrain based on data shift, we will prevent concept shift and upstream effects on predictive and business performance. Detecting data shift is our first line of defense. The higher we move on the taxonomy, the closer we are to losing business impact. We typically don't want to wait until we see degradations in business impact to retrain our model. An additional and important concept is proactive retrains. That is, we retrain our model on a schedule in the hopes of catching data shift at the earliest stages. This can often be a wise strategy. That said, we don't have to go crazy with retrains! We'll actually cover that issue more later in this chapter.
Thus far, we have mostly focused on the retraining piece of the equation. However, being able to retrain and knowing when you must retrain relates back to the issue of tracking. Fundamentally, we must know how well our model is performing in production. In other words, is what is actually happening consistent with what the model is predicting?
Current Payload Logging Process
Currently, we log input and output payloads to two locations: S3 and MySQL. This might seem duplicative, but good reason exists. S3 is highly, highly available. It will basically always be available, so it's a wonderful failsafe. However, MySQL is our ultimate destination, so it also make sense to just directly log to this location since we don't really care about response times in this case. (Responding in a few seconds is fine for our project, though this would be slow by industry standards). The issue is that while MySQL is highly available, I have experienced database outages on multiple occasions due to a variety of reasons. Therefore, we want a backup plan: S3. Of note, our MySQL table uses json datatypes for the column that stores input and output payloads. This means we can simply add and subtract fields from our payloads without breaking the logging.
ETL Logs into MySQL
Let's say we could only log to S3 from our application (which we might do to speed up our response times!), but we still wanted our logs to end up in MySQL. We could run the following as an ETL (extract, transform, and load) job on AWS Batch to accomplish this goal.
ETL Logs from S3 into DynamoDB
Let's say we only wanted to log payloads to S3 and wanted to move them over in batch to DyanmoDB. We could leverage the following script. However, a notable limitation exists if we want to run many batches over time (which is likely). We ideally want to only insert the records created after our last table insert. Unfortunately, DynamoDB doesn't give us an easy way to efficiently discover the most recent record based on the logging_timestamp. We could pull down every record and find the value in pandas, but as our table grows, this isn't a super great option.
Email Push Notifications
Sentry will alert us of errors in our application. However, it will not alert us to anomalies or other behavior of which we might want to be aware. For this purpose, we might set up an AWS Batch job that queries our logs table and triggers an email when a certain condition occurs. This might run every, say, 10 minutes. Below is a script that will simply count the number of requests and calculate the average predicted probability in a time period. If the count is above a certain threshold, an email will be triggered. Likewise, we could simply change the criteria a bit and have this be a daily report or something of the like.
SMS Push Notifications
Rather than an email, we might want to shoot off a text message. Twilio makes it quite easy to send text messages. Follow this tutorial to get started. We can then use the below function to fire off text messages using the following function.
Likewise, we can easily adjust our email notification script be more general and send an SMS notification instead.
Tracking Data Shift
Data shift is a crucial topic in machine learning. If the distributions of our features are different compared to when we trained our model, a retrain might be warranted. Without it, our model might not know how to best handle certain features. We can employ a univariate approach to track data shift. If we detect data shift, we can automatically trigger a model retrain.
Tracking Concept Shift
Concept shift is a related yet distinct concept compared to data shift. Concept shift refers to a change in the actual underlying relationship between our target and predictors. For example, activity_score was predictive, but an environmental or technological change has made it uninformative.
How does one track concept shift? With data shift, we can look at each feature and run some handy statistical tests. However, concept shift is a multivariate problem rather than a univariate one. For such a problem, we can turn to our old friend machine learning. We will pull the copy of our training data from S3, extract the input payloads from our production application, concatenate the two, and see if we can predict which rows are from production. If our test set score is above a given threshold, we ascertain that concept shift has occurred. If it doesn't, then we assert concept shift has not occurred.
Building a Model Tracking Dashboard with Streamlit
We've built some nifty tools to help us track our model. However, it might be nice to visualize such items and have access to them on demand. For that task, we can use our old buddy Streamlit. When we're building a model tracking dashboard, we should cover the following items at minimum.
- Business Impact. This is why we use machine learning! At the end of the day, we must be able to quantify the impact our model is making. In our case, this might involve estimating how many clients our model has helped save. How would we do this? In our case, this might involve comparing churn rates for clients given the "real" model vs clients given the heuristic model. We can then multiply the number of clients "saved" by some lifetime value metric to get the bottomline financial impact. What's more, we need to track this impact over time to capture any decays. One note, if we expect clients to be seen our machine learning app multiple times, we must ensure an individual client always receives eitherthe "real" model or the heuristic model.
- Predictive Performance. Do the model's predictions align with actual outcomes? I submit we care about tracking the model's calibration for this piece.
- Data Shift. As we've talked about, data shift is our first line of defense against declines in model performance. We could easily add a section for concept shift as well.
Most of the data you need about your models should be in your MySQL logs table. Depending on your situation, you might need data from a downstream system to understand how the models' predictions were used. Of course, you'll need to tie in data from your systems of record to understand the ultimate outcome (e.g. did the customer end up churning?). Below is a sample of what a model tracking dashboard might look like.
Automatic Model Retrains and Deployments
Each time we want to release a new model, we don't always want to do it manually. We want to automate this process if possible. When we retrain our model, we have two options: we can refit our existing model on new data or perform a completely new search for a "best" model. The former option is comparatively straightforward. The latter perhaps should never be automated. However, when we're refitting our model, we can do so relatively quickly and easily.
First, we need a simple retraining script. This script doesn't check for anything like data shift, but such a mechanism would be easy to build. At the moment, this is a "proactive" retraining process.
We can set the script to run on AWS Batch on whatever scheduled we like. However, how do we release this new model into production? We need to amend our CodePipeline built with Pulumi. We will add a second source step: an S3 bucket. Whenever an upload hits our s3_object_key, the CI/CD build will kick off. The CI/CD build will pull 1) code from the most recent git commit to the source CodeCommit repo and 2) the most recent file in the source S3 bucket. The file in the S3 bucket will, of course, be our pickled model that will be uploaded by retrain.py.
Likewise, we need to update our buildspec.yml file to pull our model into our Docker image. Our build process will now download the model, called model.pkl, from the S3 bucket. The Docker build step will pick up this new model.
Finally, we need to update app_settings.py and app.py. In app_settings.py, we simply need to remove MODEL_PATH. In app.py, we can also remove the import of MODEL_PATH. In our initalize_app method, we simply need to load model.pkl. For local testing, we obviously will need a local copy of a model.pkl file. We can manually pull the most recent upload from S3. Don't worry: Our buildspec.yml will remove any model.pkl file pushed into CodeCommit, making sure we use the desired S3 model. Likewise, if we are using S3 to house our models, we might list .pkl files in our .gitignore.
A Case Study on Model Retrains
I've seen some people who are retrain crazy. Let's retrain constantly! This may sound cool, but it's often overkill. In the script below, I load in a churn model and a small test set (4,000 observations). I record baseline evaluation scores on this test set. Subsequently, I change the distribution of 1-2 numeric features at varying levels and record the effect. (Of course, drift can happen in categorical features, too). This simulates drift. The results are captured in the screenshot below.
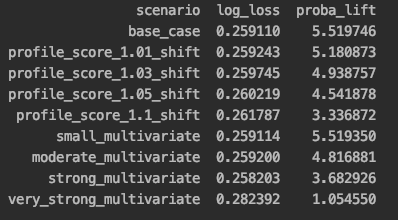
In our first scenario, we change all profile_scores by 1%. This is actually a fairly big change since we are impacting 100% of observations in some way. We can see that the impact on our predictive power is fairly small. We start getting more noticeable declines at a 5% movement of all profile_scores. When we move to a multivariate approach, our first scenario is changing the profile_score and average_stars by 1% in 10 observations. We see basically no decline in predictive performance in this scenario. We have to decently shift the data to start seeing notable declines. Of note, we see a bit of noise in the log loss for the multivariate scenarios as we are effecting random rows, some of which might not be impacted much by the selected features.
What does all this mean? The message is mixed. We clearly don't need to retrain every time we get a new observation. However, we can experience some degradation in our model even with small drift. Even though this won't tank our model, we would like to avoid such a case. Therefore, we should try to retrain proactively or at early signs of drift if possible. That said, even with some drift, our model can still work.
We have to understand our environment. How likely is drift to occur? How much drift is likely to occur? If our environment is static, we need to worry less about retraining frequently. If our data is not changing, both in terms of data and concept drift, our model will work well. Retraining becomes a proactive step. This point is important because retraining frequently may be costly in certain cases, such as when assembling the requisite data is difficult.